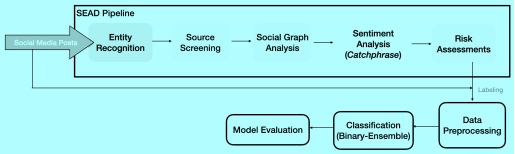
Social engineering, on the other hand, presents weaknesses that are difficult to directly quantify in penetration testing. The majority of expert social engineers utilize phishing and adware tactics to convince victims to provide information voluntarily. Social Engineering (SE) in social media has a similar structural layout to regular postings but has a malevolent intrinsic purpose. Recurrent Neural Network-Long Short-Term Memory (RNN-LSTM) was used to train a novel SE model to recognize covert SE threats in communications on social networks. The dataset includes a variety of posts, including text, images, and videos. It was compiled over a period of several months and was carefully curated to ensure that it is representative of the types of content that is typically posted on social media. First, by using domain heuristics, the social engineering assaults detection (SEAD) pipeline is intended to weed out social posts with malevolent intent. After tokenizing each social media post into sentences, each post is examined using a sentiment analyzer to determine whether it is a training data normal or an abnormality. Subsequently, an RNN-LSTM model is trained to detect five categories of social engineering assaults, some of which may involve information-gathering signals. Comparing the experimental findings to the ground truth labeled by network experts, the SEA model achieved 0.82 classification precision and 0.79 recall.
| Published in | American Journal of Operations Management and Information Systems (Volume 9, Issue 1) |
| DOI | 10.11648/j.ajomis.20240901.12 |
| Page(s) | 17-24 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Artificial Neural Network, Cybersecurity, Machine Learning, Random Forest Classifier, Social Engineering Attack
2.1. Data Input Analysis
2.2. Detection Method Based
2.3. Data Labeling and Risk Analysis
3.1. Datasets and Attack Classes
SEA Types | Training | Testing | ||
|---|---|---|---|---|
Instance Count | Word Count | Instance Count | Word Count | |
Pretexting | 810 | 10102 | 205 | 2356 |
Phishing | 810 | 11978 | 205 | 2056 |
Scareware | 810 | 8013 | 205 | 1985 |
Clickbaits | 810 | 10010 | 205 | 2435 |
Quid Pro Quo | 810 | 9284 | 205 | 2006 |
3.2. Performance Assessment
Algorithm | Precision | Recall |
|---|---|---|
DT(j47) | 0.74 | 0.69 |
DBN | 0.59 | 0.50 |
KNN | 0.72 | 0.65 |
RF | 0.80 | 0.74 |
PCA | 0.53 | 0.44 |
DNN(LSTM) | 0.85 | 0.79 |
| [1] | Aldawood, H., & Skinner, G. (2019). Educating and Raising Awareness on Cyber Security Social Engineering: A Literature Review. December, 62–68.(Aldawood & Skinner, 2019) |
| [2] | Tanwar, S., Paul, T., Singh, K., Joshi, M., & Rana, A. (2020). Classification and Imapct of Cyber Threats in India: A review. ICRITO 2020 - IEEE 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions), 129–135. |
| [3] | Ajagbe, S. A., & Adigun, M. O. (2023). Deep learning techniques for detection and prediction of pandemic diseases: a systematic literature review. In Multimedia Tools and Applications (Issue 0123456789). Springer US. |
| [4] | Dasgupta, S., Piplai, A., Kotal, A., & Joshi, A. (2020). A Comparative Study of Deep Learning based Named Entity Recognition Algorithms for Cybersecurity. Proceedings - 2020 IEEE International Conference on Big Data, Big Data 2020, 2596–2604. |
| [5] | Lorenzen, C., Agrawal, R., & King, J. (2019). Determining Viability of Deep Learning on Cybersecurity Log Analytics. Proceedings - 2018 IEEE International Conference on Big Data, Big Data 2018, April, 4806–4811. |
| [6] | Gümüşbaş, D., Yıldırım, T., Genovese, A., & Scotti, F. (2021). A comprehensive survey of databases and deep learning methods for cybersecurity and intrusion detection systems. IEEE Systems Journal, 15(2), 1717–1731. |
| [7] | Shaukat, K., Luo, S., Varadharajan, V., Hameed, I. A., & Xu, M. (2020). A Survey on Machine Learning Techniques for Cyber Security in the Last Decade. IEEE Access, 8, 222310–222354. |
| [8] | Temitope S. Adekunle; Morolake O. Lawrence; Oluwaseyi O. Alabi; Adenrele A. Afolorunso; Godwin N. Ebong; Matthew A. Oladipupo. (2023). Deep Learning for Plant Disease Detection. Computer Science and Information Technologies, 5(1), 49–56. |
| [9] | Algarni, A., Xu, Y., & Chan, T. (2017). An empirical study on the susceptibility to social engineering in social networking sites: The case of Facebook. European Journal of Information Systems, 26(6), 661–687. |
| [10] | Bakhshi, T. (2018). Social engineering: Revisiting end-user awareness and susceptibility to classic attack vectors. Proceedings - 2017 13th International Conference on Emerging Technologies, ICET2017, 2018-Janua, 1–6. |
| [11] | Naidoo, R. (2020). A multi-level influence model of COVID-19 themed cybercrime. European Journal of Information Systems, 29(3), 306–321. |
| [12] | Dan, A., & Gupta, S. (2019). Social engineering attack detection and data protection model (SEADDPM). In Advances in Intelligent Systems and Computing (Vol. 811, Issue January). Springer Singapore. |
| [13] | de Coning, A., & Mouton, F. (2020). Water distribution network leak detection management. European Conference on Information Warfare and Security, ECCWS, 2020-June(June), 89–97. |
| [14] | Shafiei, D., Mostafavi, S. A., & Mehrabadi, S. J. (2023). Geometrical optimization of city gate station’s water bath indirect heater to minimization of fuel consumption. Journal of Thermal Engineering, 9(4), 841–860. |
| [15] | Giboney, J. S., Schuetzler, R. M., & Grimes, G. M. (2021). Developing a measure of adversarial thinking in social engineering scenarios. Proceedings of the 16th Pre-ICIS Workshop on Information Security and Privacy, 1–15. |
| [16] | Berman, D. S., Buczak, A. L., Chavis, J. S., & Corbett, C. L. (2019). A survey of deep learning methods for cyber security. Information (Switzerland), 10(4). |
| [17] | Wu, Y., Wei, D., & Feng, J. (2020). Network attacks detection methods based on deep learning techniques: A survey. Security and Communication Networks, 2020. |
| [18] | Vinayakumar, R., Alazab, M., Soman, K. P., Poornachandran, P., Al-Nemrat, A., & Venkatraman, S. (2019). Deep Learning Approach for Intelligent Intrusion Detection System. IEEE Access, 7(c), 41525–41550. |
| [19] | Le, T. T. H., Kim, J., & Kim, H. (2017). An Effective Intrusion Detection Classifier Using Long Short-Term Memory with Gradient Descent Optimization. 2017 International Conference on Platform Technology and Service, PlatCon 2017 - Proceedings, February. |
| [20] | Zhang, T. tian, Elsakka, M., Huang, W., Wang, Z. guo, Ingham, D. B., Ma, L., & Pourkashanian, M. (2019). Winglet design for vertical axis wind turbines based on a design of experiment and CFD approach. Energy Conversion and Management, 195(February), 712–726. |
| [21] | Akande, T. O., Alabi, O. O., & Ajagbe, S. A. (2024). A Deep Learning-Based CAE Approach For Simulating 3D Vehicle Wheels Under Real-World Conditions. Journal of Artificial Intelligence and Applications, 1–16. |
| [22] | Aun, Y., Gan, M. L., Wahab, N. H. B. A., & Hock Guan, G. (2023). Social Engineering Attack Classifications on Social Media Using Deep Learning. Computers, Materials and Continua, 74(3), 4917–4931. |
| [23] | Abdulmajeed Aljuhani, & Abdulaziz Alhubaishy. (2020). 3rd ICCAIS 2020 : International Conference on Computer Applications & Information Security : 19-21 March, 2020, Riyadh, Kingdom of Saudi Arabia. Incorporating a Decision Support Approach within the Agile Mobile Application Development Process, 23–26. |
| [24] | Luo, Z., Cai, W., Li, Y., & Peng, D. (2011). The correlation between social tie and reciprocity in social media. Proceedings of 2011 International Conference on Electronic and Mechanical Engineering and Information Technology, EMEIT 2011, 8, 3909–3911. |
| [25] | Alexan, W., Mamdouh, E., Elbeltagy, M., Ashraf, A., Moustafa, M., & Al-Qurashi, H. (2022). Social Engineering and Technical Security Fusion. International Telecommunications Conference, ITC-Egypt 2022 - Proceedings, August. |
| [26] | Ojo, O. S., Oyediran, M. O., Bamgbade, B. J., Adeniyi, A. E., Ebong, G. N., & Ajagbe, S. A. (2023). Development of an Improved Convolutional Neural Network for an Automated Face Based University Attendance System. ParadigmPlus, 4(1), 18–28. |
| [27] | Ajagbe, S. A., Adegun, A. A., Olanrewaju, A. B., Oladosu, J. B., & Adigun, M. O. (2023). Performance investigation of two-stage detection techniques using traffic light detection dataset. IAES International Journal of Artificial Intelligence, 12(4), 1909–1919. |
APA Style
Adekunle, T. S., Lawrence, M. O., Alabi, O. O., Ebong, G. N., Ajiboye, G. O., et al. (2024). The Use of AI to Analyze Social Media Attacks for Predictive Analytics . American Journal of Operations Management and Information Systems, 9(1), 17-24. https://doi.org/10.11648/j.ajomis.20240901.12
ACS Style
Adekunle, T. S.; Lawrence, M. O.; Alabi, O. O.; Ebong, G. N.; Ajiboye, G. O., et al. The Use of AI to Analyze Social Media Attacks for Predictive Analytics . Am. J. Oper. Manag. Inf. Syst. 2024, 9(1), 17-24. doi: 10.11648/j.ajomis.20240901.12
AMA Style
Adekunle TS, Lawrence MO, Alabi OO, Ebong GN, Ajiboye GO, et al. The Use of AI to Analyze Social Media Attacks for Predictive Analytics . Am J Oper Manag Inf Syst. 2024;9(1):17-24. doi: 10.11648/j.ajomis.20240901.12
@article{10.11648/j.ajomis.20240901.12,
author = {Temitope Samson Adekunle and Morolake Oladayo Lawrence and Oluwaseyi Omotayo Alabi and Godwin Nse Ebong and Grace Oluwamayowa Ajiboye and Temitope Abiodun Bamisaye},
title = {The Use of AI to Analyze Social Media Attacks for Predictive Analytics
},
journal = {American Journal of Operations Management and Information Systems},
volume = {9},
number = {1},
pages = {17-24},
doi = {10.11648/j.ajomis.20240901.12},
url = {https://doi.org/10.11648/j.ajomis.20240901.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajomis.20240901.12},
abstract = {Social engineering, on the other hand, presents weaknesses that are difficult to directly quantify in penetration testing. The majority of expert social engineers utilize phishing and adware tactics to convince victims to provide information voluntarily. Social Engineering (SE) in social media has a similar structural layout to regular postings but has a malevolent intrinsic purpose. Recurrent Neural Network-Long Short-Term Memory (RNN-LSTM) was used to train a novel SE model to recognize covert SE threats in communications on social networks. The dataset includes a variety of posts, including text, images, and videos. It was compiled over a period of several months and was carefully curated to ensure that it is representative of the types of content that is typically posted on social media. First, by using domain heuristics, the social engineering assaults detection (SEAD) pipeline is intended to weed out social posts with malevolent intent. After tokenizing each social media post into sentences, each post is examined using a sentiment analyzer to determine whether it is a training data normal or an abnormality. Subsequently, an RNN-LSTM model is trained to detect five categories of social engineering assaults, some of which may involve information-gathering signals. Comparing the experimental findings to the ground truth labeled by network experts, the SEA model achieved 0.82 classification precision and 0.79 recall.
},
year = {2024}
}
TY - JOUR T1 - The Use of AI to Analyze Social Media Attacks for Predictive Analytics AU - Temitope Samson Adekunle AU - Morolake Oladayo Lawrence AU - Oluwaseyi Omotayo Alabi AU - Godwin Nse Ebong AU - Grace Oluwamayowa Ajiboye AU - Temitope Abiodun Bamisaye Y1 - 2024/04/02 PY - 2024 N1 - https://doi.org/10.11648/j.ajomis.20240901.12 DO - 10.11648/j.ajomis.20240901.12 T2 - American Journal of Operations Management and Information Systems JF - American Journal of Operations Management and Information Systems JO - American Journal of Operations Management and Information Systems SP - 17 EP - 24 PB - Science Publishing Group SN - 2578-8310 UR - https://doi.org/10.11648/j.ajomis.20240901.12 AB - Social engineering, on the other hand, presents weaknesses that are difficult to directly quantify in penetration testing. The majority of expert social engineers utilize phishing and adware tactics to convince victims to provide information voluntarily. Social Engineering (SE) in social media has a similar structural layout to regular postings but has a malevolent intrinsic purpose. Recurrent Neural Network-Long Short-Term Memory (RNN-LSTM) was used to train a novel SE model to recognize covert SE threats in communications on social networks. The dataset includes a variety of posts, including text, images, and videos. It was compiled over a period of several months and was carefully curated to ensure that it is representative of the types of content that is typically posted on social media. First, by using domain heuristics, the social engineering assaults detection (SEAD) pipeline is intended to weed out social posts with malevolent intent. After tokenizing each social media post into sentences, each post is examined using a sentiment analyzer to determine whether it is a training data normal or an abnormality. Subsequently, an RNN-LSTM model is trained to detect five categories of social engineering assaults, some of which may involve information-gathering signals. Comparing the experimental findings to the ground truth labeled by network experts, the SEA model achieved 0.82 classification precision and 0.79 recall. VL - 9 IS - 1 ER -
Department of Computer Science, Colorado State University, Fort Collins, USA
Department of Computer Science, Baze University, Abuja, Nigeria
Department of Mechanical Engineering, Lead City University, Ibadan, Nigeria
Department of Data Science, University of Salford, Salford, UK
Department of Computer Science, Precious Cornerstone University, Ibadan, Nigeria
Department of Computer Science, National Open University of Nigeria, Abuja, Nigeria

Figure 1. The Pipeline for Social Media Engineering Attack Classifications (Aun et al., 2023).

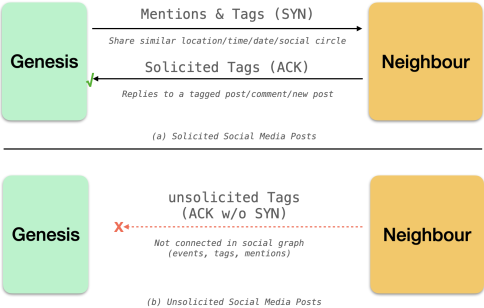
Figure 2. Depending on the interaction state, calculating the maliciousness index of social media posts. A legitimate post in (a) must be asking for previous encounters. If there haven't been any past interactions between the circles, a post with similar semantics in (b) gets red-flagged (Aun et al., 2023).
Information